
Performance Characterization of Suricata's Thread Models
In a previous project my fellow Amit Sheoran and I examined how well Suricata IDS runs inside Docker container and virtual machine environments. In April 2017, we further examined Suricata’s various thread models, as a project for Purdue CS525 Parallel Computing course. In this article we first introduce the thread models, and then compare them in terms of performance and resource utilization.
Suricata’s Multi-Thread Architecture
Compared to Snort IDS, the biggest feature of Suricata is that it adopts multi-threaded design to achieve high performance. In a high-level picture, the design consists of four thread modules and three runmodes.
Thread Modules
A thread module can be seen as a type of work to process a packet. There are four major thread modules:
- Packet acquisition – Acquires packets from network.
- Decode and Stream Application layer – Decodes the data and handles TCP reassembly, etc.
- Detection – Matches the decoded data against Rules.
- Output – Deals with logging, and alerting.
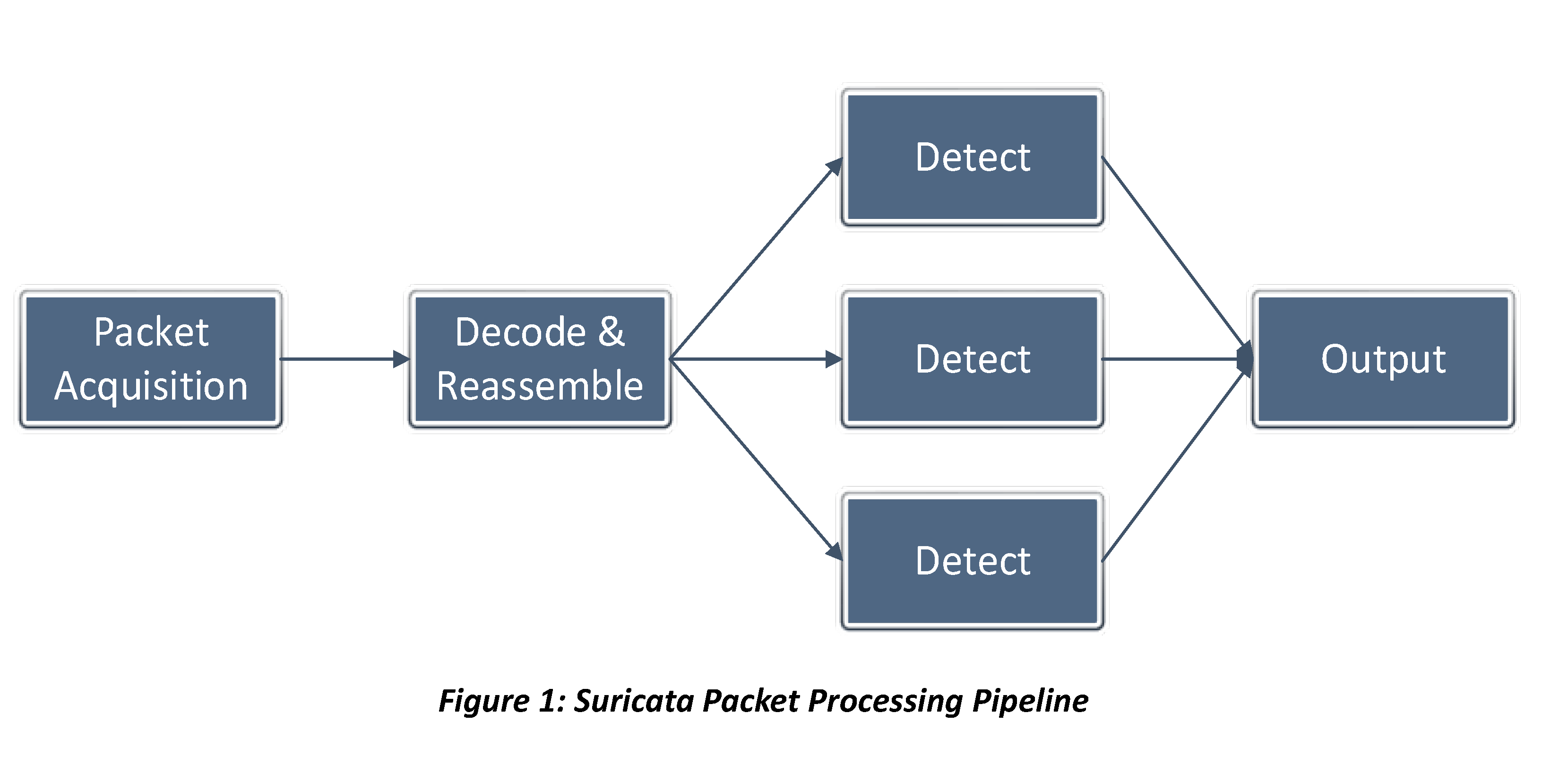
Each thread can execute one or more thread module, depending on the runmode configuration.
Runmodes
Suricata supports multiple runmodes to handle incoming packets:
- Single – Single-threaded mode.
- AutoFP – The task of processing a packet is pipelined to multiple stages. Each thread handles one stage, and there is at least one thread in a stage.
- Workers – Multiple workers, each of which single-handedly processes the packets it acquires (i.e., each thread runs all thread modules).
AutoFP Mode
In AutoFP mode, multiple threads try to acquire packets, and then put the packets to next stage of the pipeline for further processing. We refer to threads on packet acquisition stage as packet acquisition threads (PAQ), threads decoding packets as decoders, etc.
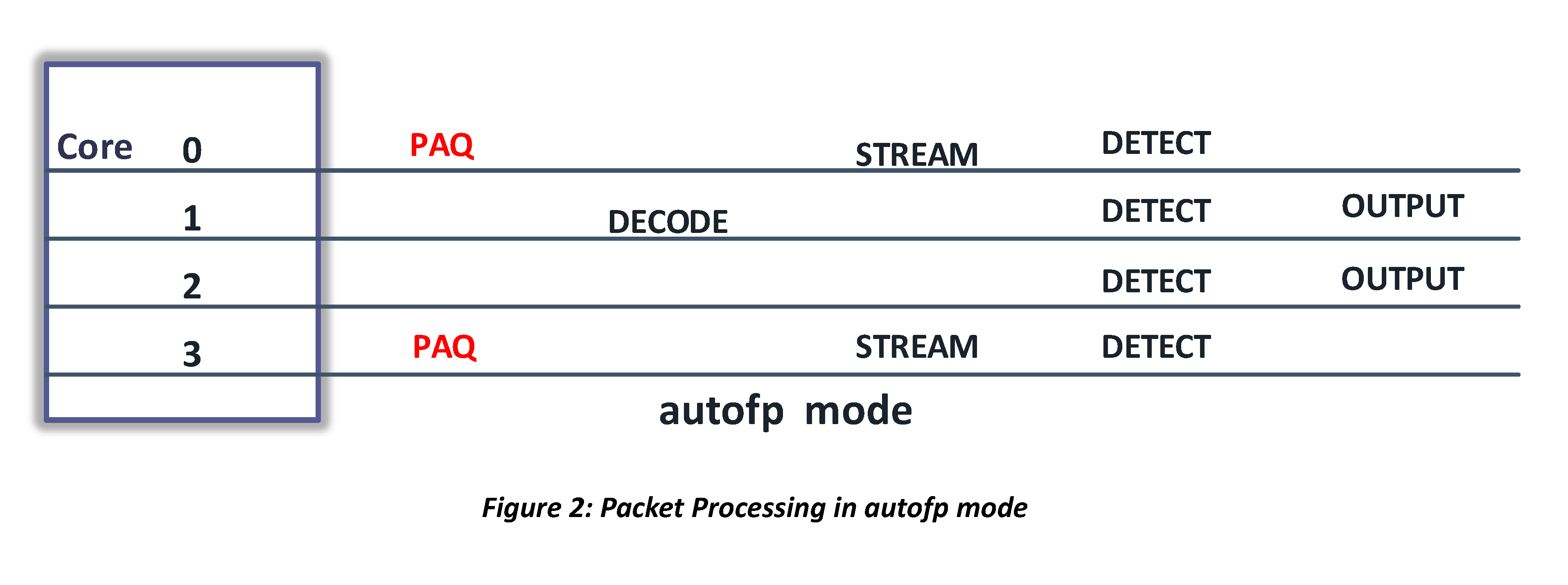
Workers Mode
In “workers” mode, multiple threads can receive packets and the thread that receives the packet executes all thread modules to process the packet.
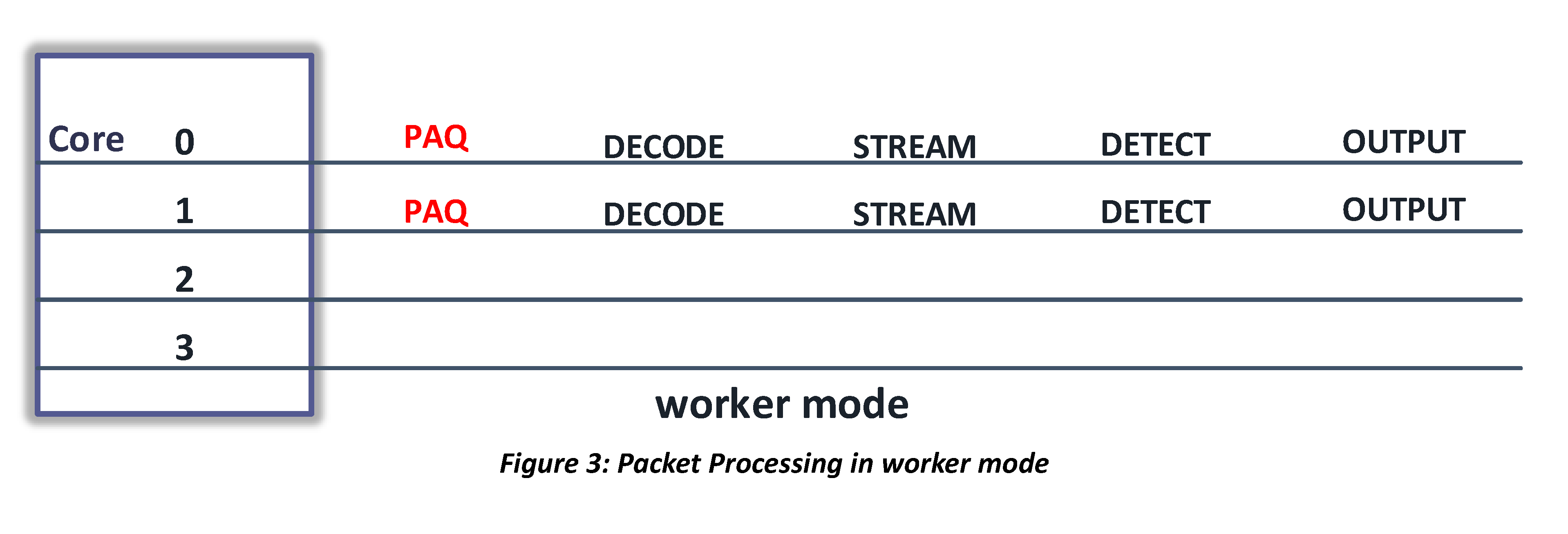
Single Mode
Single mode is equivalent to workers mode with one worker thread.
Test Methodology
We rely on the test environment setup we made in NFV project, and tweak the following parameters in the Suricata config:
- Runmode = {autofp, workers}
- Number of (packet capture threads, decoding threads) = (1, 1) to (16, 32).
- Number of NICs
against various levels of workload generated by iperf (which turned out not doing well) and TCPreplay, and then collect performance and resource usage metrics. Suricata runs on bare metal.
Testbed Spec
Both sender and receiver hosts have the following hardware spec:
- CPU: 2x Intel Xeon E5-2620 v4 @ 2.10GHz, 2 Sockets, 8 Cores Per Socket with HT disabled.
- RAM: 64 GB
- NICs: Intel I-350 Gigabit Ethernet
and runs Ubuntu Server 16.04.2 LTS. The tests were based on Suricata 3.2, but there haven’t been significant changes to its thread model as of Dec 2017.
Experiment with iperf
When using iperf, we use multiple client-server pairs to generate traffic, which can be pure TCP or UDP packets. We also tweak packet size, bandwidth, and number of parallel streams. Iperf server end runs on the same machine as Suricata, and one NIC can be used by one or more iperf pair.
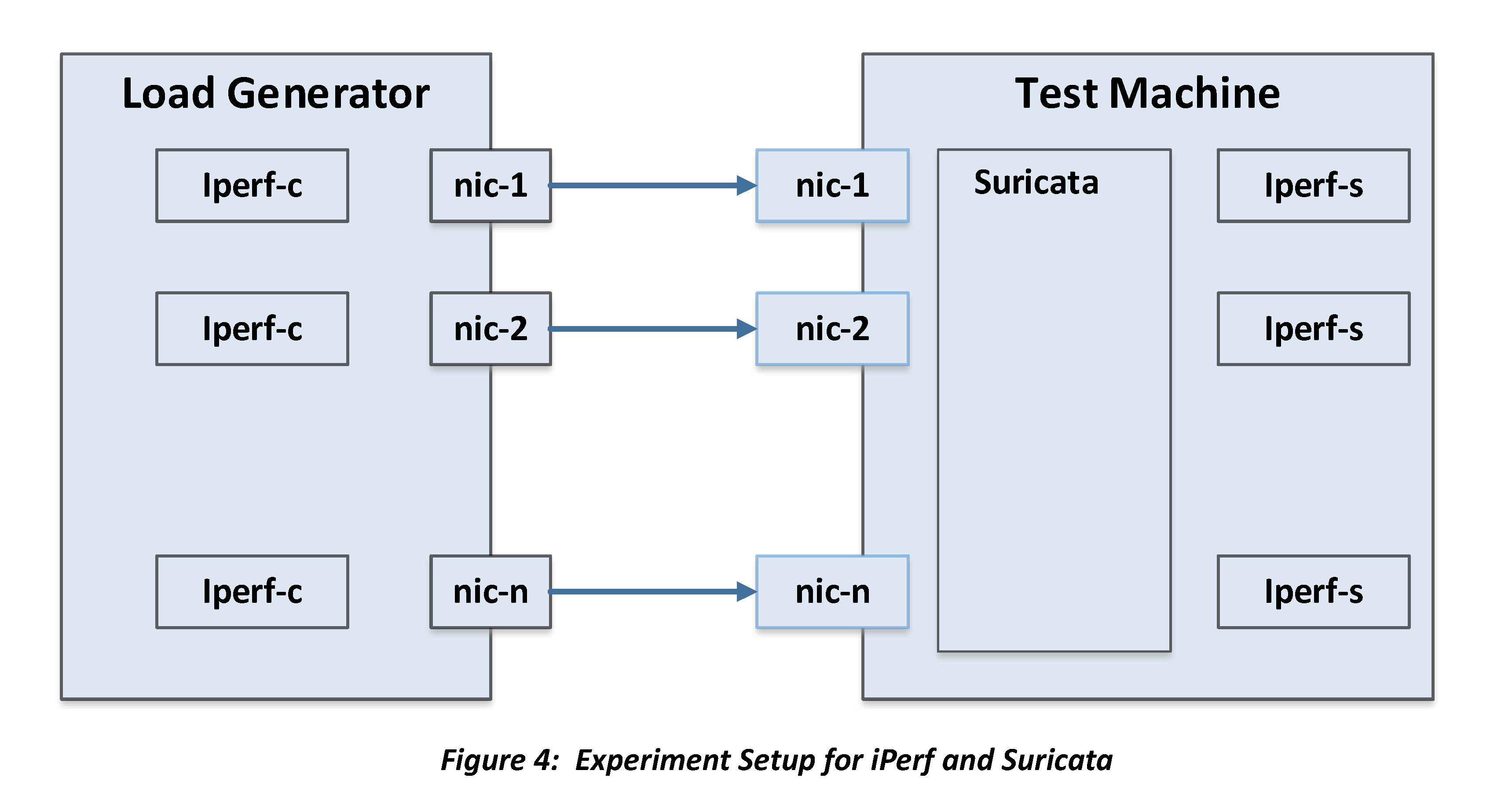
However, there is one issue with iperf approach. In order to compare thread models of Suricata, we need controllable, constant packets-per-second (pps) workload during stress test. And since packet payload does not matter much to Suricata and our NIC is 1Gbps, packets must be small. Due to TCP congestion control, pps from iperf varies greatly over time and is beyond our control.
Figure 5 shows the number of packets generated by iperf over time for one of the test runs. pps varies over time, but throughput (bps) is kept constant over this entire duration. iperf automatically increases the packet size when packet generation rate falls.
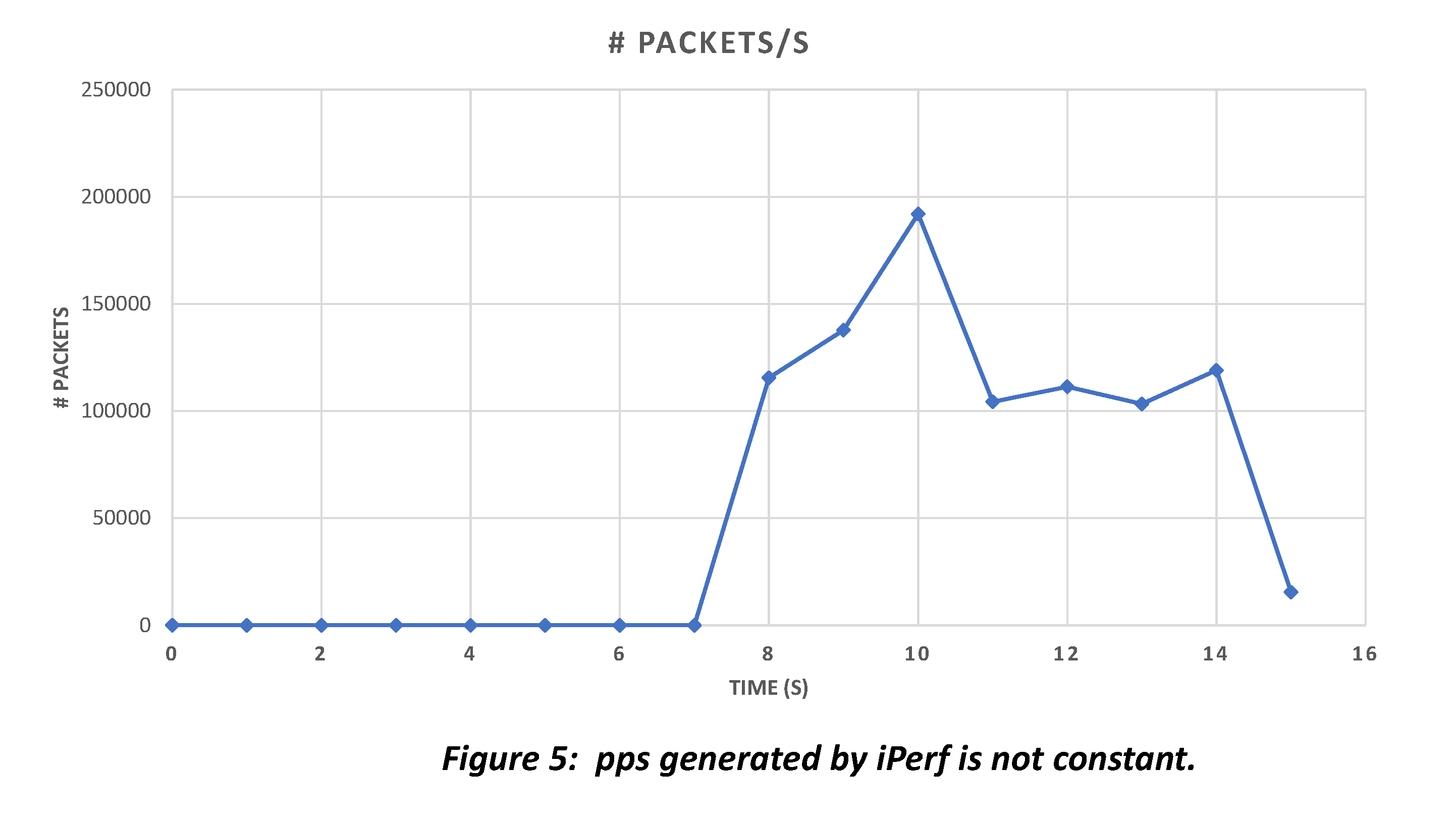
Since pps generated by iperf is neither constant nor controllable over time, the total number of packets sent to Suricata for handling differs for each iteration of the same test. Therefore, we cannot guarantee all packet drops are due to Suricata, and data points generated by iperf cannot be used as a basis for comparison. We resort to TCPreplay to generate workload instead.
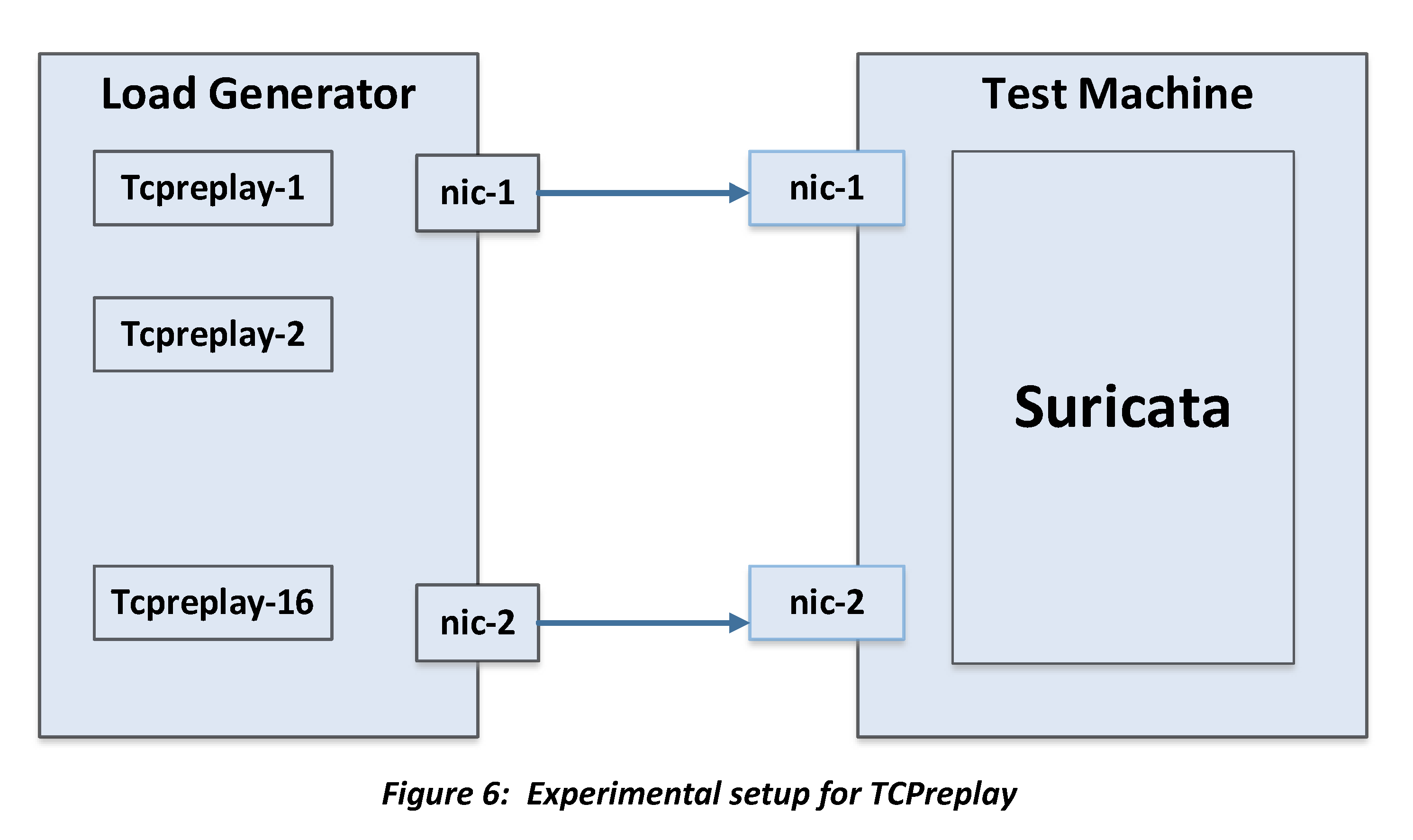
Experiment with TCPreplay
TCPreplay replays a trace file onto a NIC notwithstanding network condition, so
the behavior is reproducible across runs. We use the ISTS’12 trace introduced in
our previous Suricata project, snort.log.1425823194, as workload traffic. It
generates ~55.42 Mbps at 6264.04 pps for approx. 22 seconds. To generate more
workload, up to 16 instances of TCPreplay per NIC are run concurrently. As a
baseline, we verified that the testbed system is capable of handling peak
workload of 16 TCPreplay instances without packet drop. All reported drops are
therefore caused by Suricata.
Evaluating Performance and Resource Usage
The result is kind of surprising.
Result of AutoFP Mode
Scalability
Figure 7a shows the comparison of Suricata performance, in terms of the number of packets decoded vs. packets dropped, with 1 PAQ and 1, 2 and 4 decoders. It can be seen that performance does not scale with the number of decoders – 4 decoders do not do better than 1 decoder at 16X workload, while there is no resource bottleneck. This is also the case when 2 PAQ threads are used, as shown by Figure 7b.
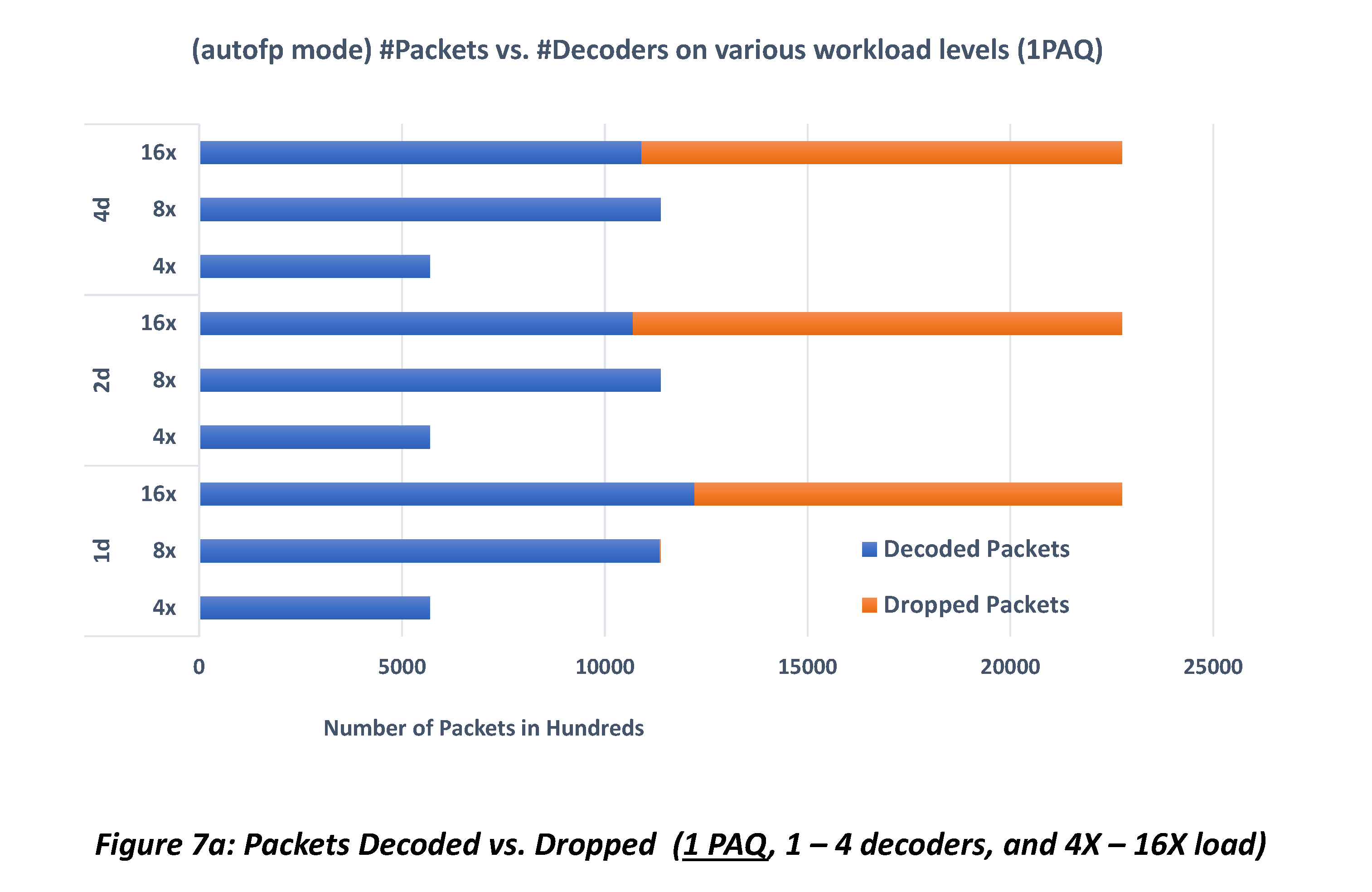
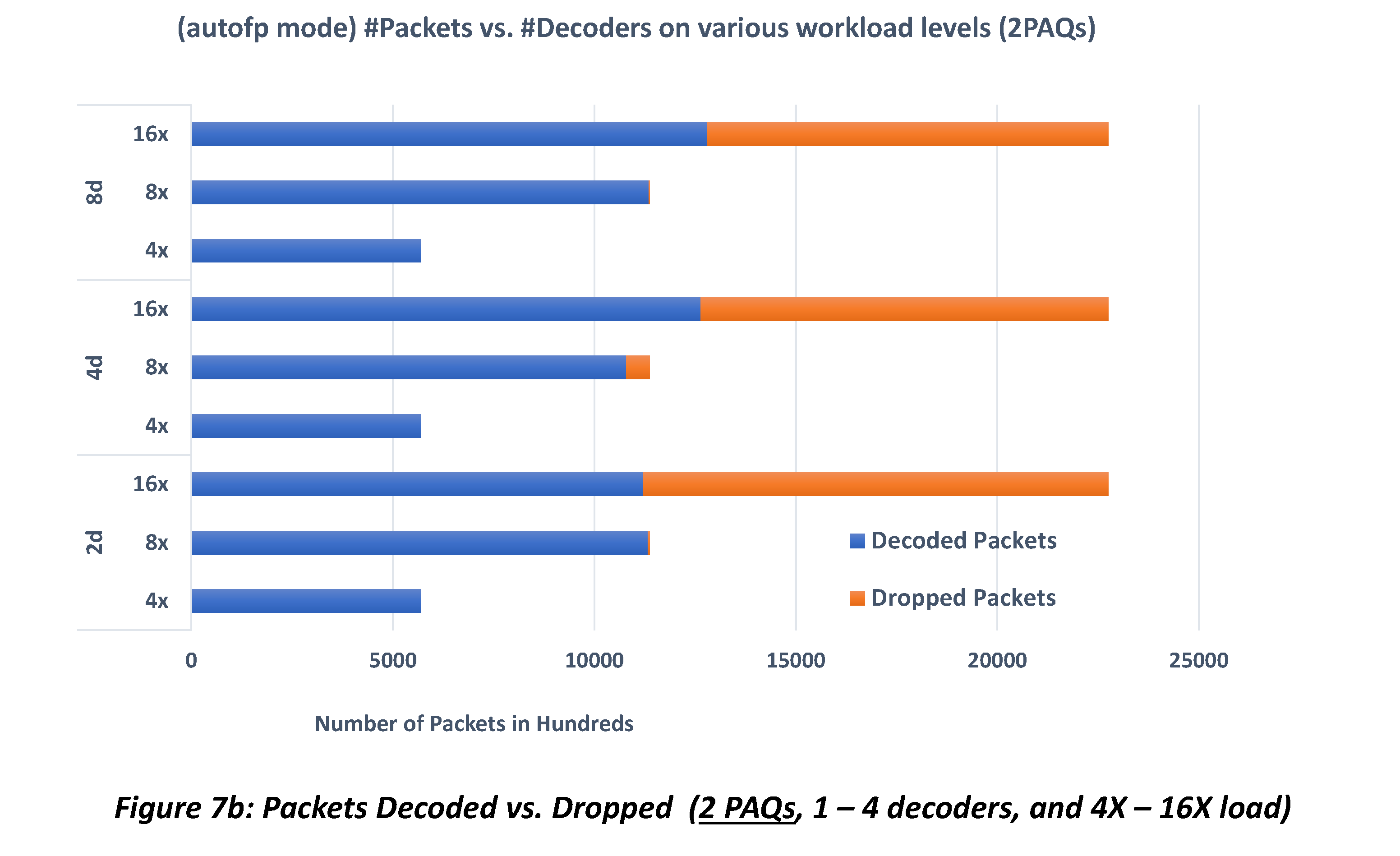
Comparing the two plots vertically, we see that performance does not scale with the number of PAQ threads, either.
Resource Usage
Figure 8a shows the CPU usage and the number of packets processed by Suricata in autofp mode with 8X load. CPU usage increases roughly linearly to the number of packet acquisition threads (PAQ); however, this does not translate to performance gain. RAM usage (not shown in the figure) increases sub-linearly and is not a bottleneck. The pattern shows again on 16X load.
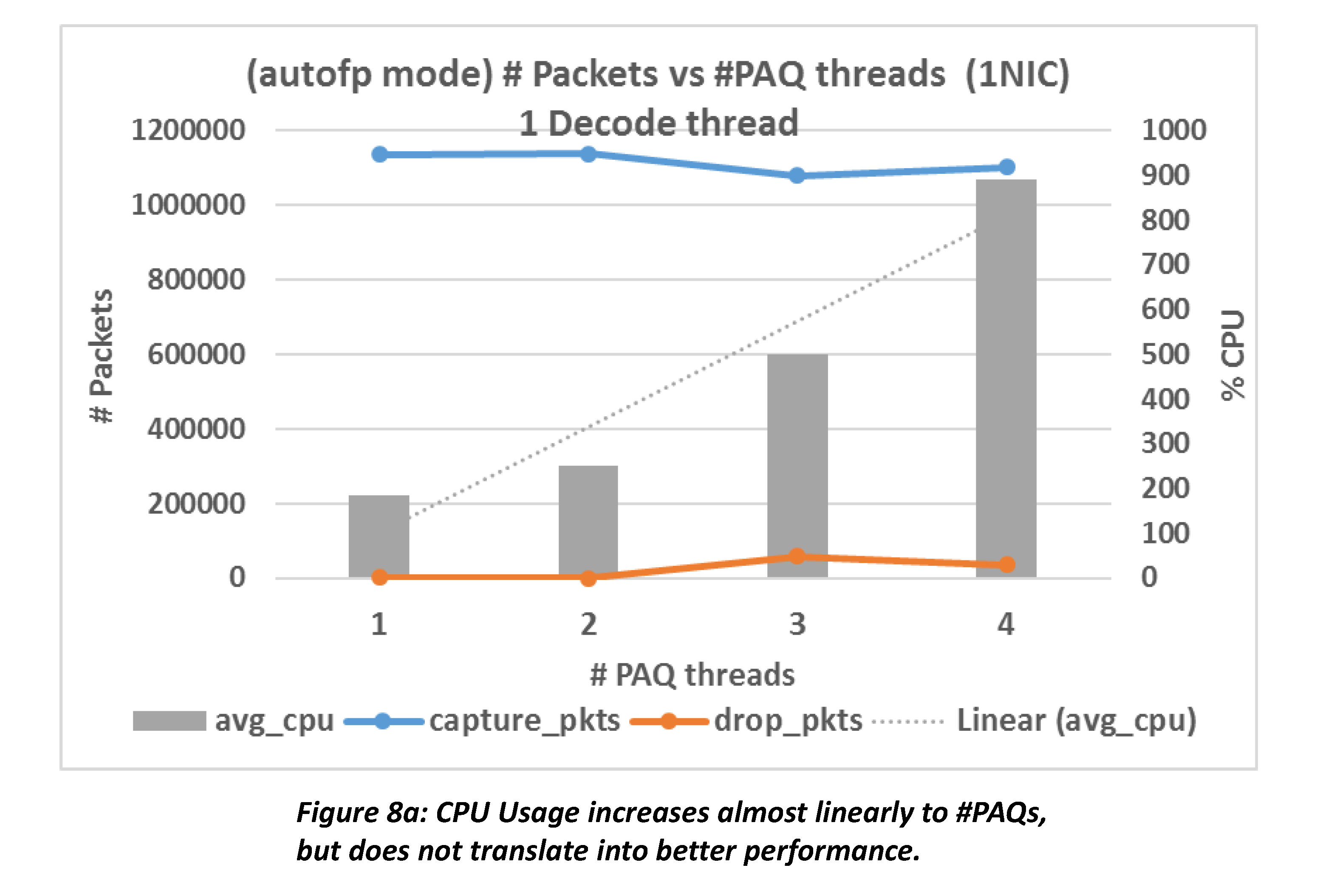
Worrying that it could be a bottleneck to have only one decoder thread, we plotted figure 8b where there are two decoders. We see that CPU usage drops on nodes PAQ={3, 4} but increases on nodes PAQ={1, 2}.
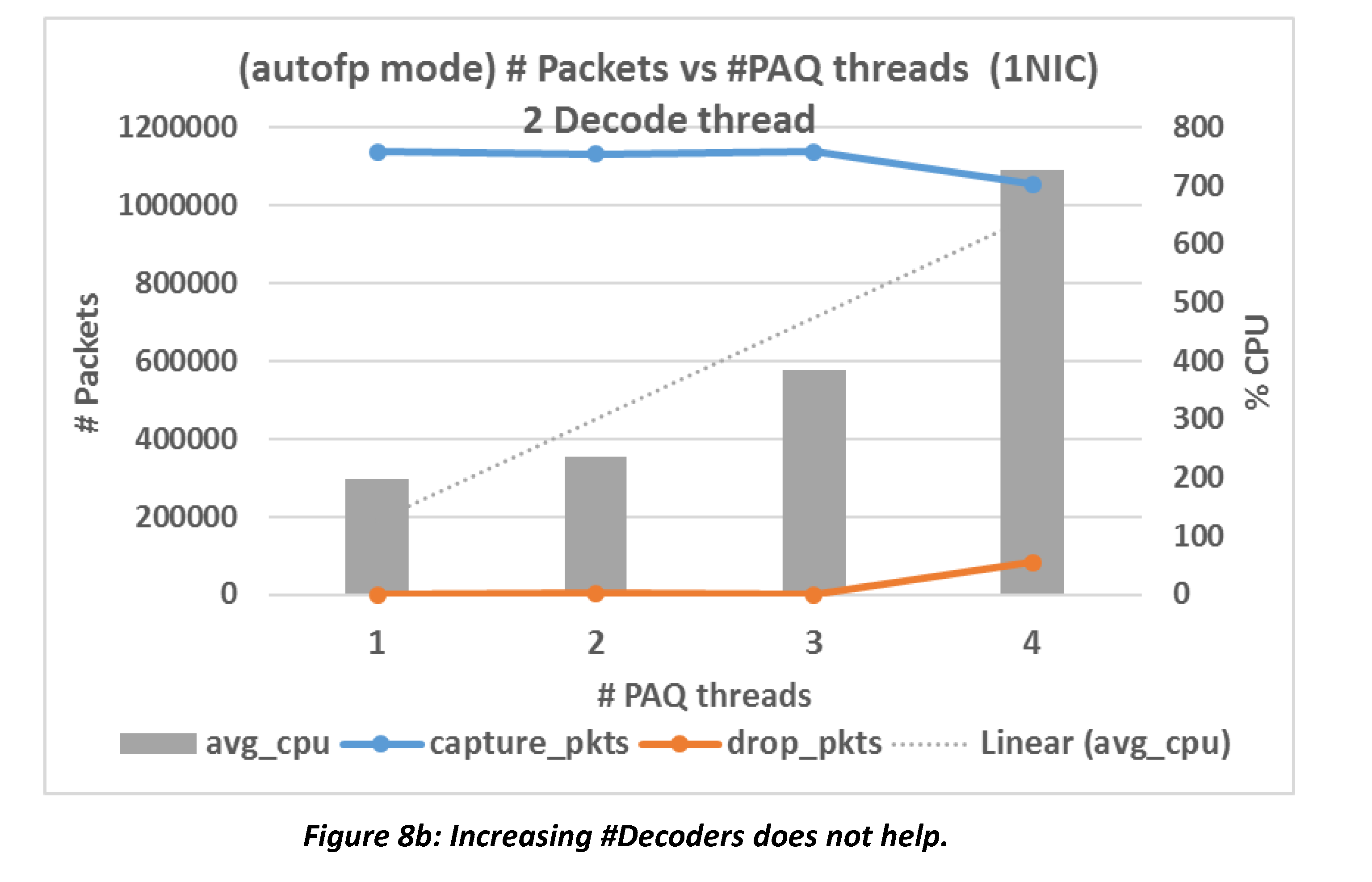
It’s also noteworthy that with more threads, Suricata becomes less capable to handle the traffic it manages to handle with fewer threads.
Multiple NICs
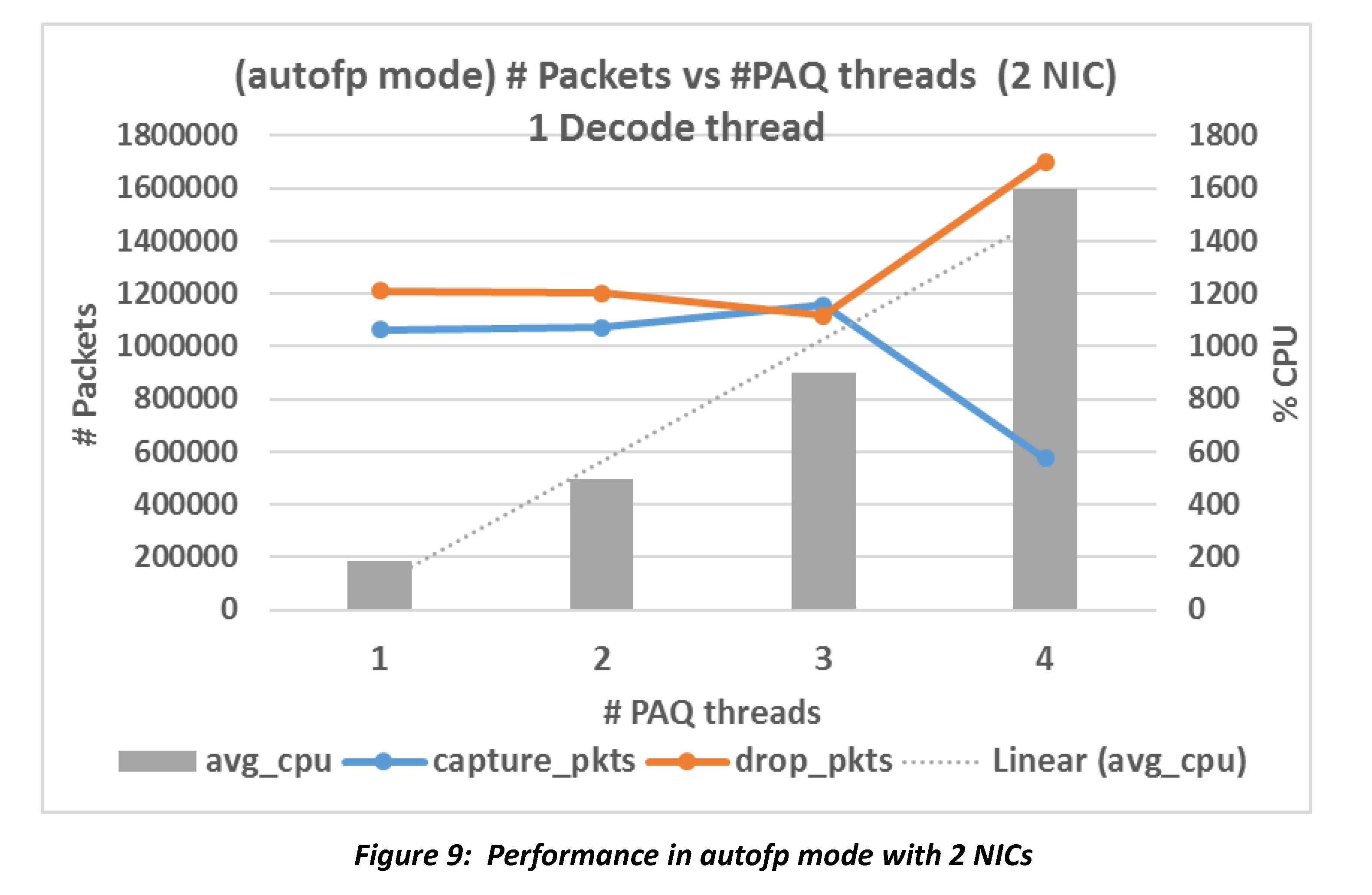
Figure 9 shows the performance in autofp mode with 2 NICs. Compare it with Figure 8a and we see that Suricata does not handle more packets even though the traffic could have been dealt with “with more freedom”. Besides, CPU usage almost doubles at nodes PAQ={2, 3, 4}, but more than half of total traffic is dropped.
Summary
We see that on autofp runmode:
- Performance does not scale with the number of packet acquisition threads or decoder threads;
- CPU usage increases almost linearly with the number of PAQ threads, but it does not translate to performance improvement;
- Performance does not improve when traffic is distributed on different NICs.
In all data points, we never see a speedup > 1.13 (in terms of packets processed) for autofp mode.
Results – Workers Mode
Workers mode differs from autofp mode in that a packet, once captured, is never transferred to another thread for processing. So in workers mode, there is no distinction between PAQ threads and decoder threads. It’s verified both from code and from experiment that in this mode, Suricata takes the number PAQ threads from config and ignores the number of decoder threads.
As seen from figure 10, performance gets worse as the number of worker threads increases, while CPU usage increases. However, CPU usage seems capped to 200%.
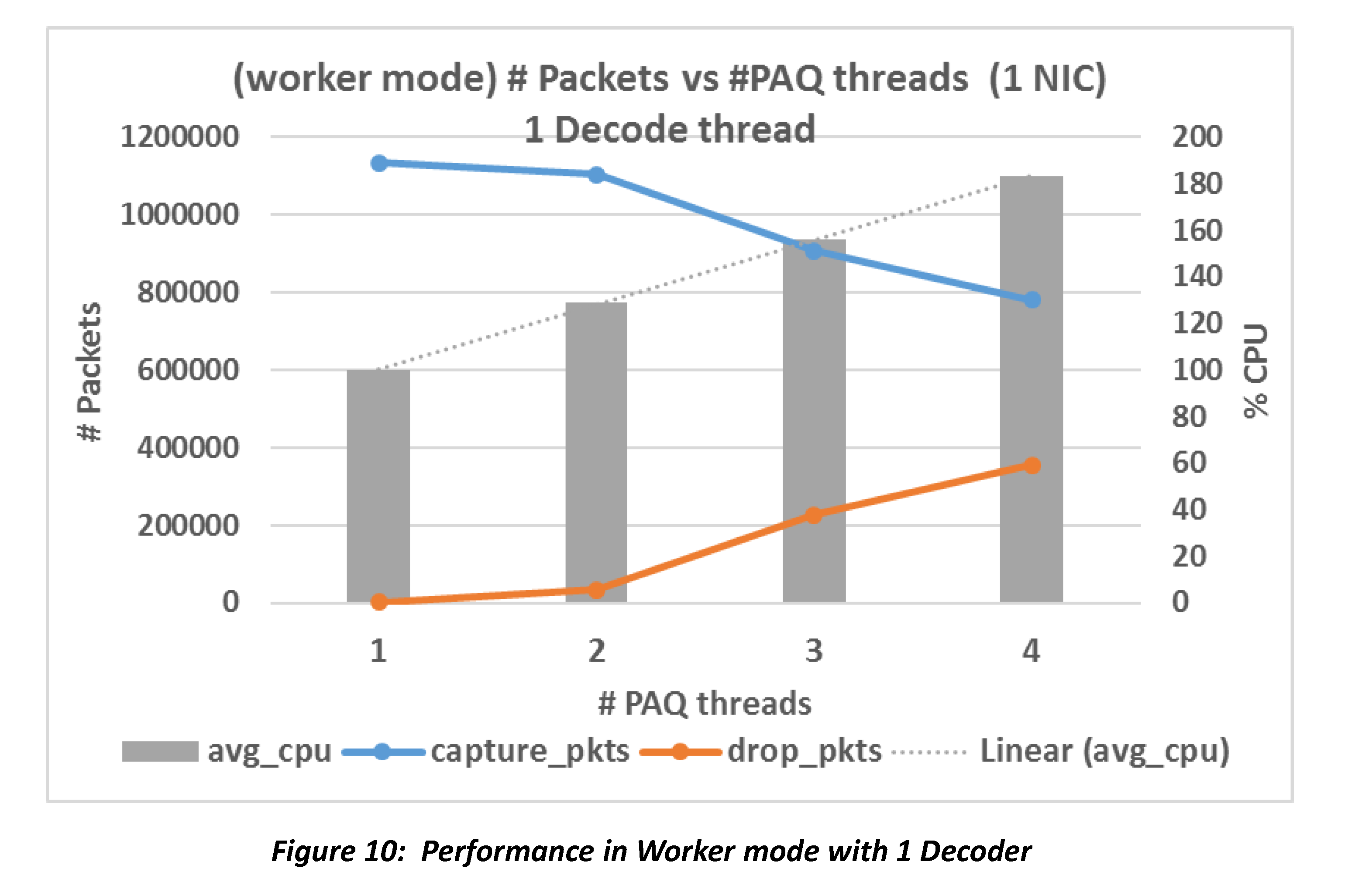
Figure 11 is almost the same as figure 10. This confirms that the number of decoder threads config is not used in workers mode.
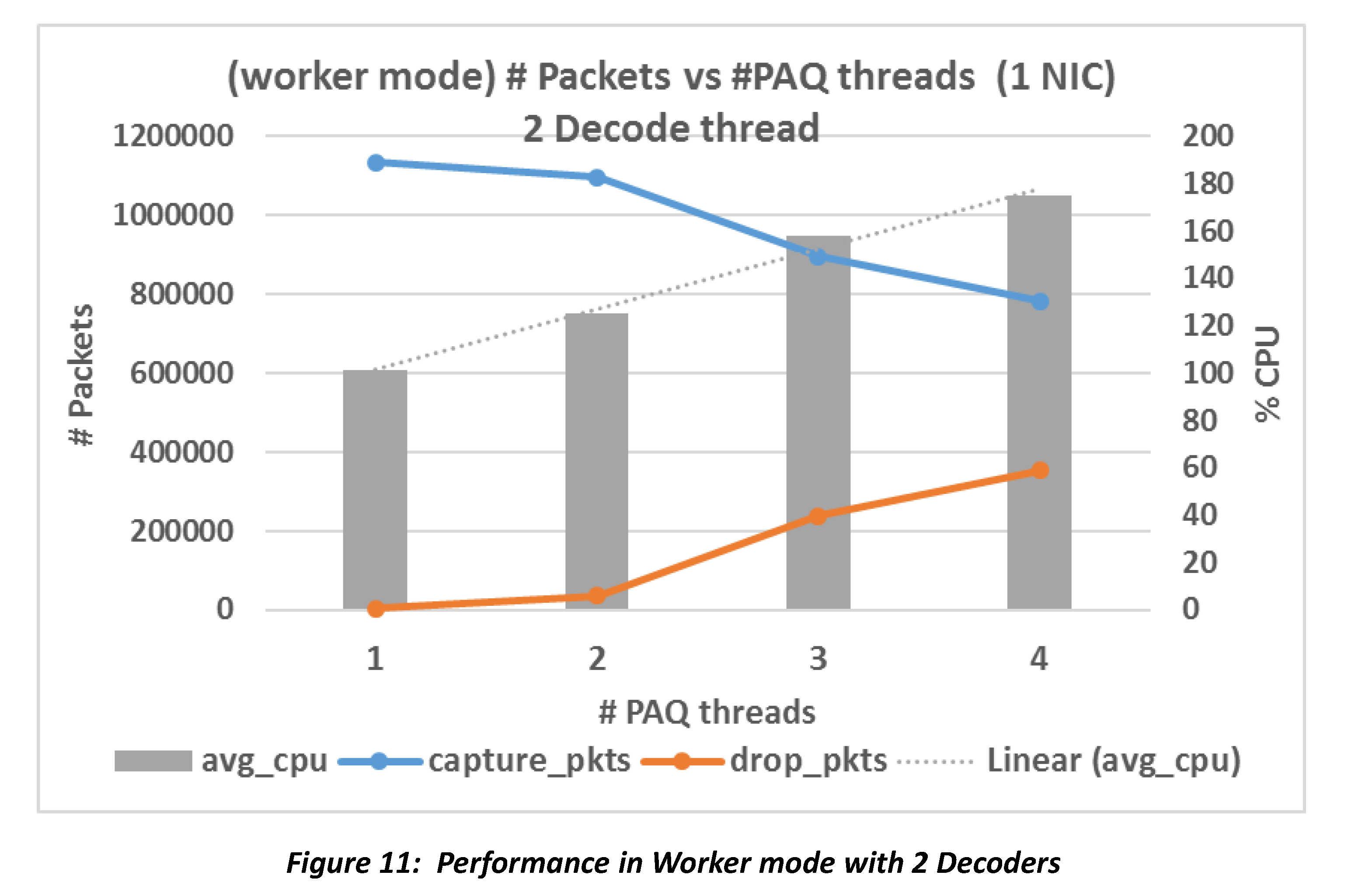
Figure 12 shows the performance in worker mode with 2 NICs. The total number
of worker threads is #NICs * #PAQs, but still, about half of total traffic
is dropped no matter how we increase the number of threads.
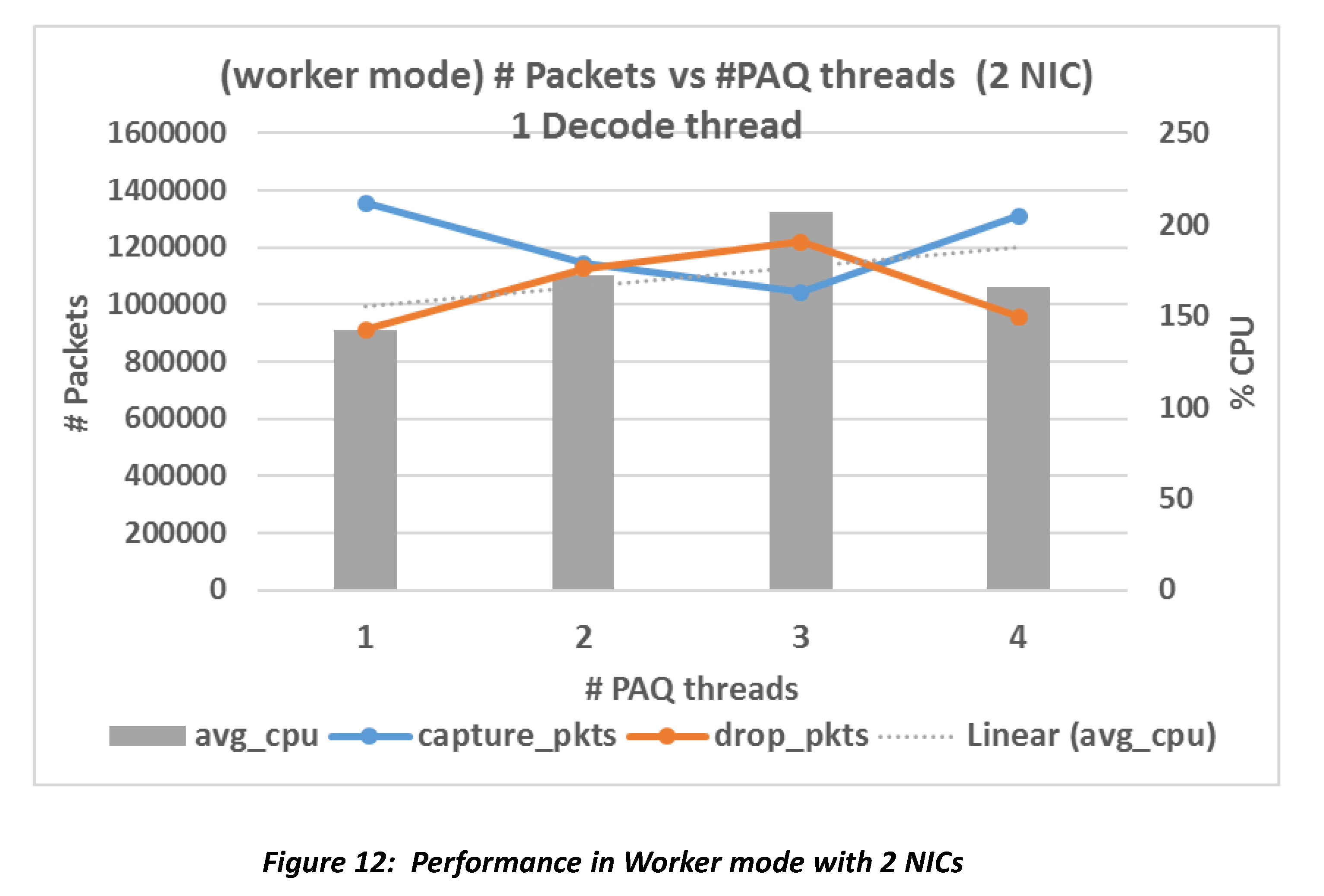
Summary
Performance of the system gets worse as the number of threads increases, but resource usage does not increase as sharply as in autofp mode. In all the data points, the best speedup we see is 1.28 for workers mode.
Analyzing Runmodes with Intel vTune
Intel vTune is a tool for software performance analysis. We used it to further analyze the unexpected result of Suricata thread models.
AutoFP Mode
The analysis was based on running Suricata with 8 PAQ threads and 4 decoder threads, 8X workload, and 2 NICs.
It confirmed what we observed from the experiment that AutoFP mode has higher level of concurrency compared to Workers mode. The average CPU usage is ~1000%. However, recall that the performance does not improve even though more resource is used.
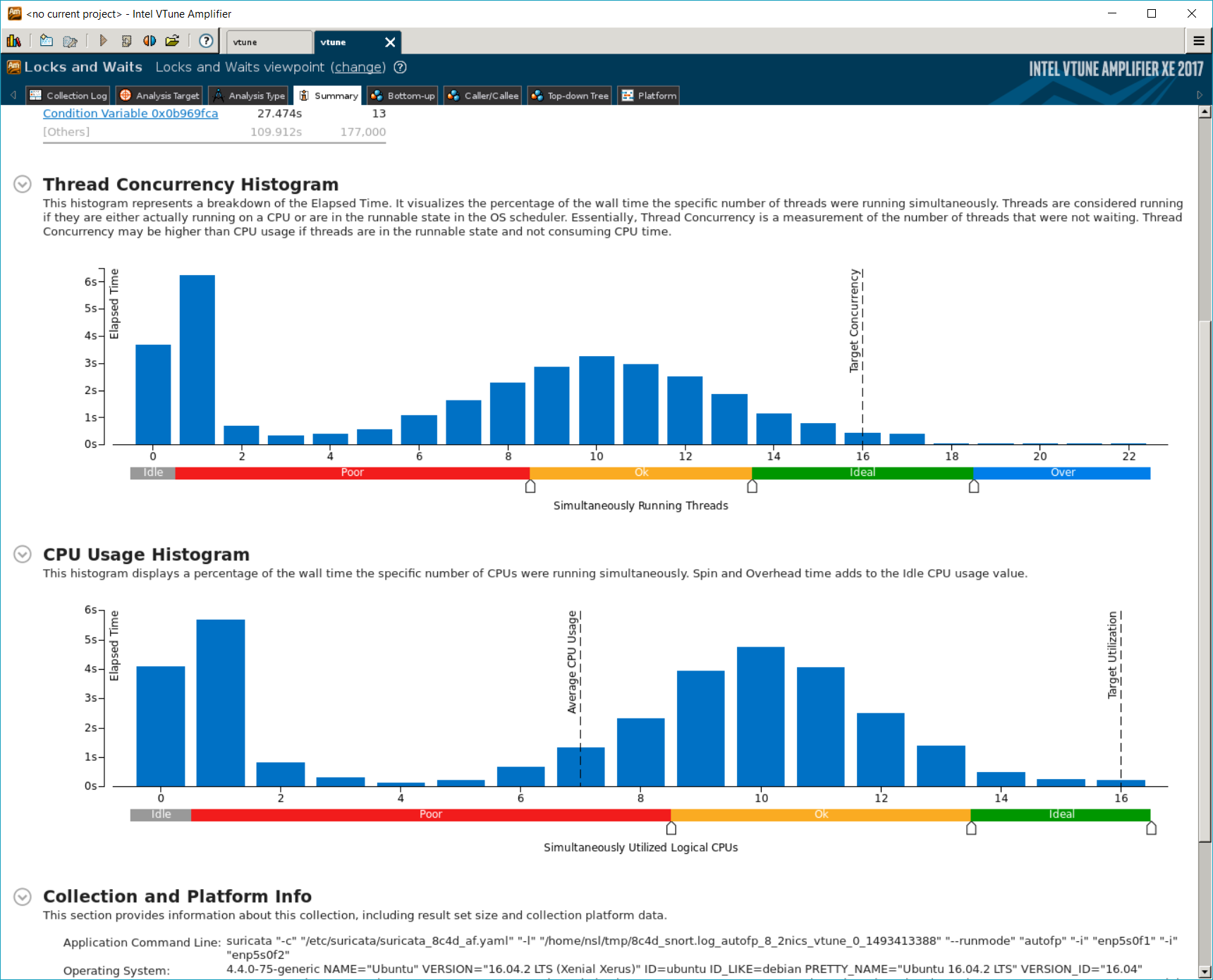
Contentions
With the help of Locks and Waits analysis of Intel vTune, we see that the
majority of CPU resource is spent on poll(). The second point of contention
is a condition variable to receive packets from the queue.
This is also reflected in the lower part of the screenshot. The 16 PAQ threads (“RX” threads) are busy polling I/O events, and the worker threads (“W” threads) are mostly idle. The load is not balanced in neither PAQ threads nor decoder threads.
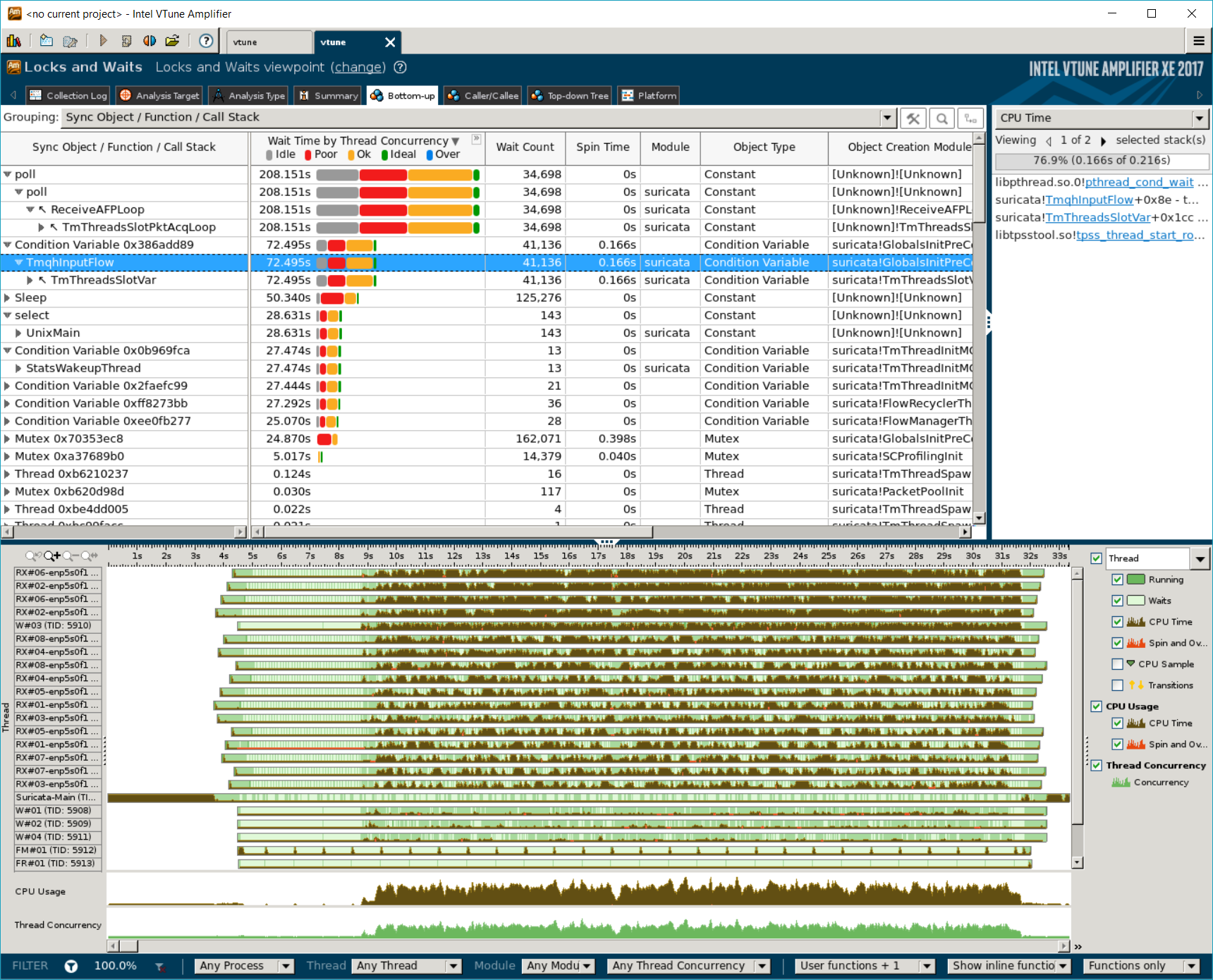
Workers Mode
Intel vTune confirmed that Workers mode had poor degree of thread concurrency and barely used more than two cores during its execution. The following screenshots are from analyzing Suricata with 8 workers, 8X workload, and 2 NICs. Note that Suricata creates 8 workers for each NIC, so there are 16 workers in total.
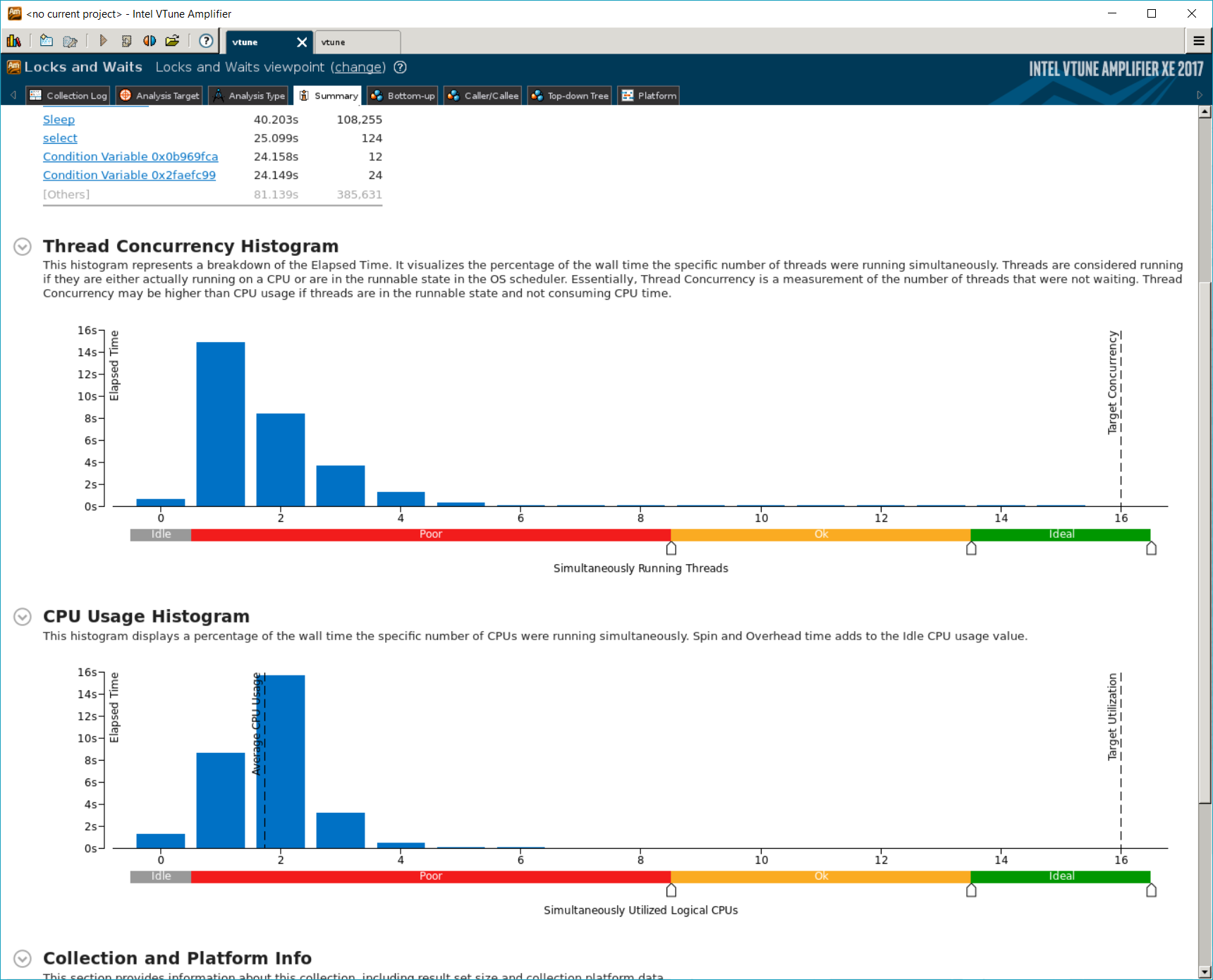
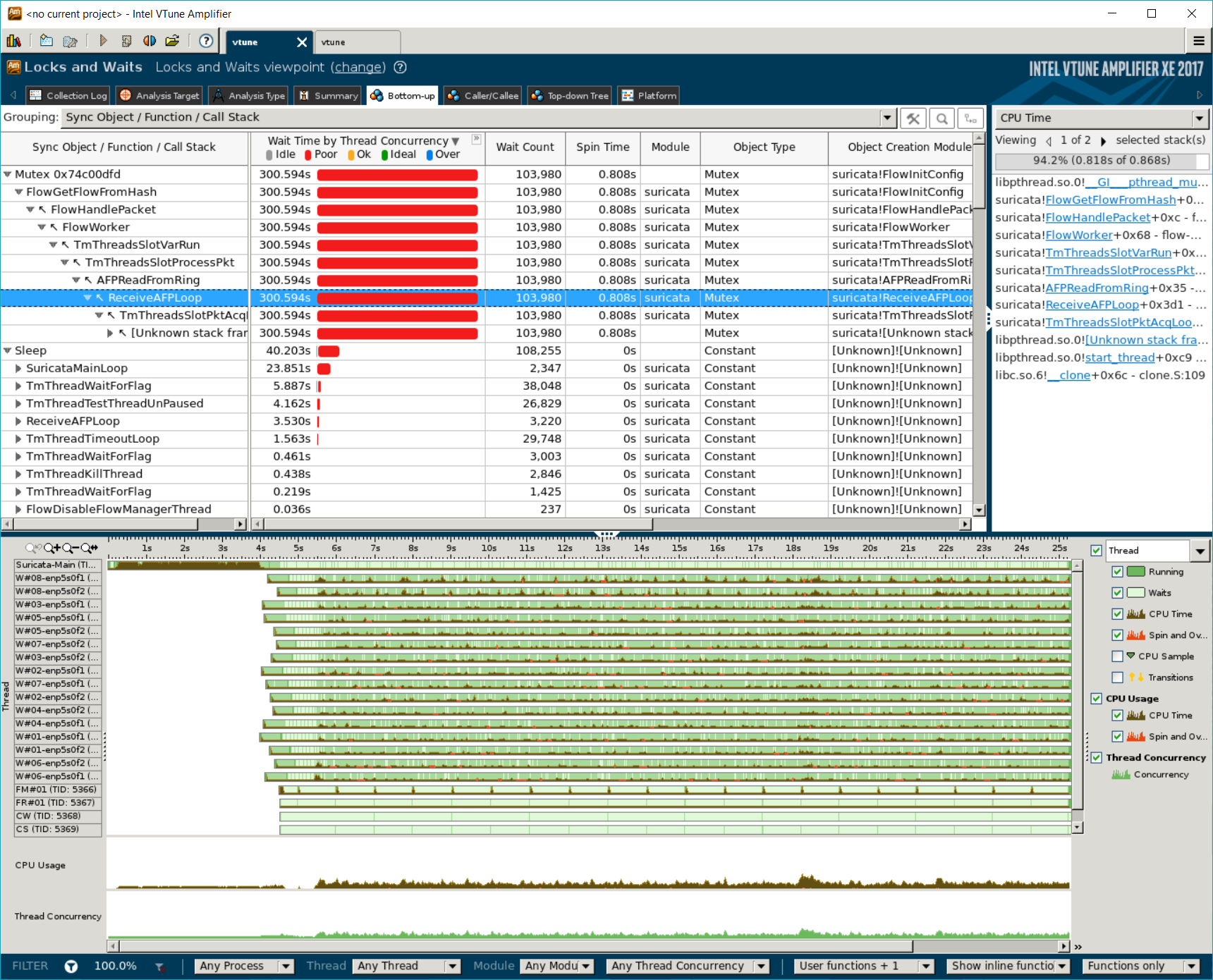
Contentions
We see that the mutex to control fetching flows from hash is a major point of contention. About 300 seconds out of ~360 seconds’ execution is spent here. Besides, the load among the 16 workers (8 workers per NIC) is highly imbalanced, even though the TCPreplay processes provide same load.
Conclusion
While more threads lead to higher resource usage (particularly in autofp mode), they do not translate into better performance for Suricata. From what we observed, neither multi-thread modes of Suricata scale to the number of available cores:
- AutoFP mode (Speedup <= 1.13)
- Trivial to no speedup with increased number of PAQ or decoder threads.
- Exhibits linear CPU usage increase, however, by wasting most of CPU cycles in polling.
- Workers mode (Speedup <= 1.28)
- Exhibits worse performance than AutoFP mode but uses less resource.
- Hardly uses more than two CPU cores due to mutex contention.
And neither modes scale to the number of NICs.
The multi-thread design does not give Suricata the scalability it wants. To improve performance, redesigning and benchmarking a new thread model is imperative and contentions must be reduced by as much as possible.